FooocusUI的绘图体验评测V1.0(针对二次元动漫绘图)
2023 / 8 / 30

简单地体验和评测一下FooocusUI
先给出今天使用的所有资源及其链接
一、初见Fooocus
首先,我们来看官方介绍。
官方介绍了许多Fooocus的优势,包括:
-
自动调节参数,用户注意力可以更加集中于提示词的书写(如同使用midjourney)。
-
不需要像webui和comfyui一样先在文生图工作流中使用base模型,再在图生图工作流中使用refiner模型。相较于前二者需要间断性地使用两次K采样器,Fooocus可以在一次成图工作中先后连续地使用base模型和refiner模型,两个模型只在一个采样器内进行工作,保证了采样的连续性。(webui的开发版中也出现了这个功能)
-
支持ADM来补偿高分辨率图像中CFG对比度的不足(这一效果目前没有明显感知)
-
Fooocus的SAG(一个生成图像的参数,与图像对比度有关,SAG越高,图像对比度越高,相应地也会带来细节提升)经过了精心优化,不会产生过于平滑的结果。(需要说明的是,在SD-webui中,也有调控SAG的插件SAG降噪优化 可以实现类似的效果,但这个插件并不广为人知)。
-
有多种样式模版,可以快速选择自己喜欢的样式。
二、下载和安装
官方文档给出的下载安装教程非常简单。

需要注意的是,Fooocus只支持基于SDXL的模型,并且在第一次启动的时候会自动下载SDXL的两个大模型。
由于我本人电脑中没有SDXL原本的大模型,只有基于SDXL训练出的若干个动漫模型,我就尝试把那些动漫模型的文件名改成Fooocus需要下载的两个XL模型的文件名,实测是可以启动成功的!如果你没有任何SDXL的大模型,你也可以通过程序自动下载。不论如何,你能很轻松地开始体验Fooocus。
尽管下载和安装都非常简单,但是仍然有不少地方需要吐槽。
首先,这并不是我第一次切换UI了,当初从webui切换到comfyui的时候,comfyui为了让用户不再重复地下载模型,给出了一个extra\*model\*path.yaml文件,让用户能够通过填写webui中的模型路径,很方便地使用comfyui调用自己原先下载到webui的模型。
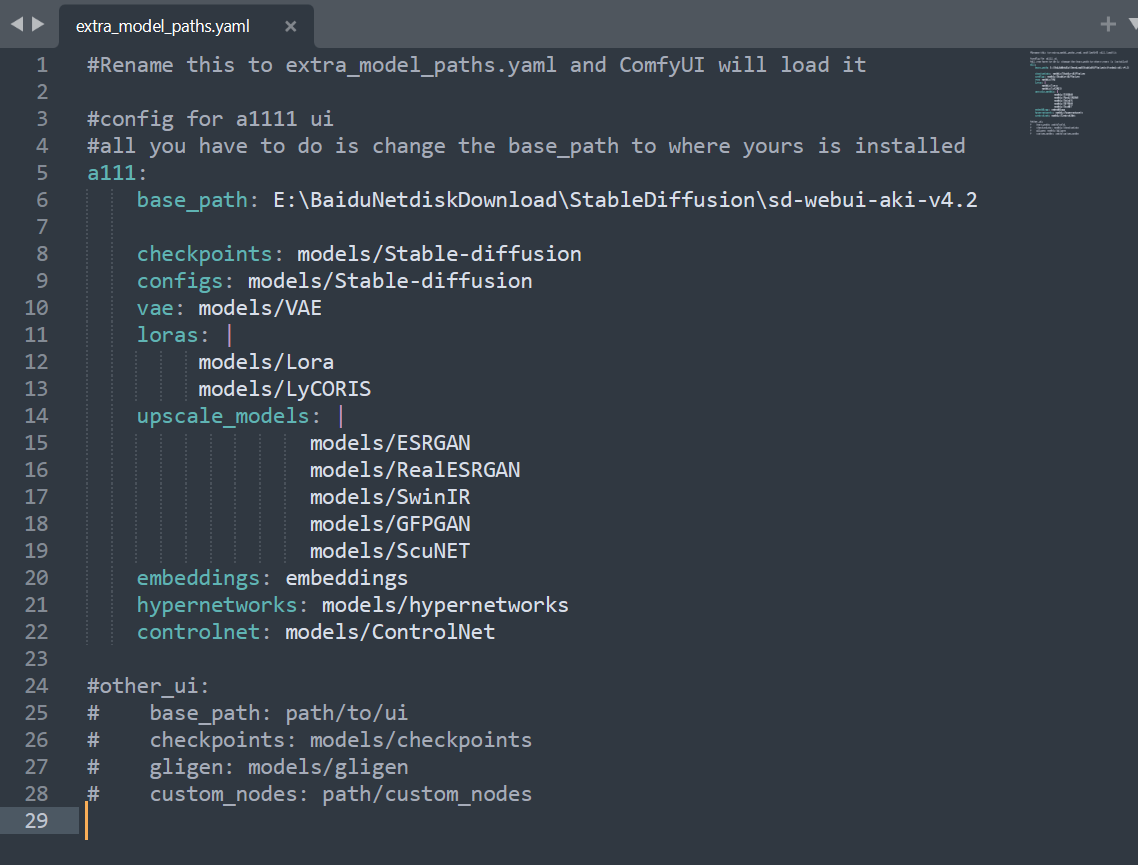
在Fooocus中,我并没有找到这样类似的文档,意味着用户并不能在fooocus中调用自己在别的UI中下载的模型,这会造成极大的空间浪费。
另外,如果你使用了VPN服务,你就有概率遇到“虽然启动成功但是网页一直报错”的问题(这个问题我在discussions中也发现有人遇到了,复现步骤就是开启VPN的全局模式)。

三、初见UI界面
如果你不开启Advance功能,那么这个界面就是你能看到的全部。
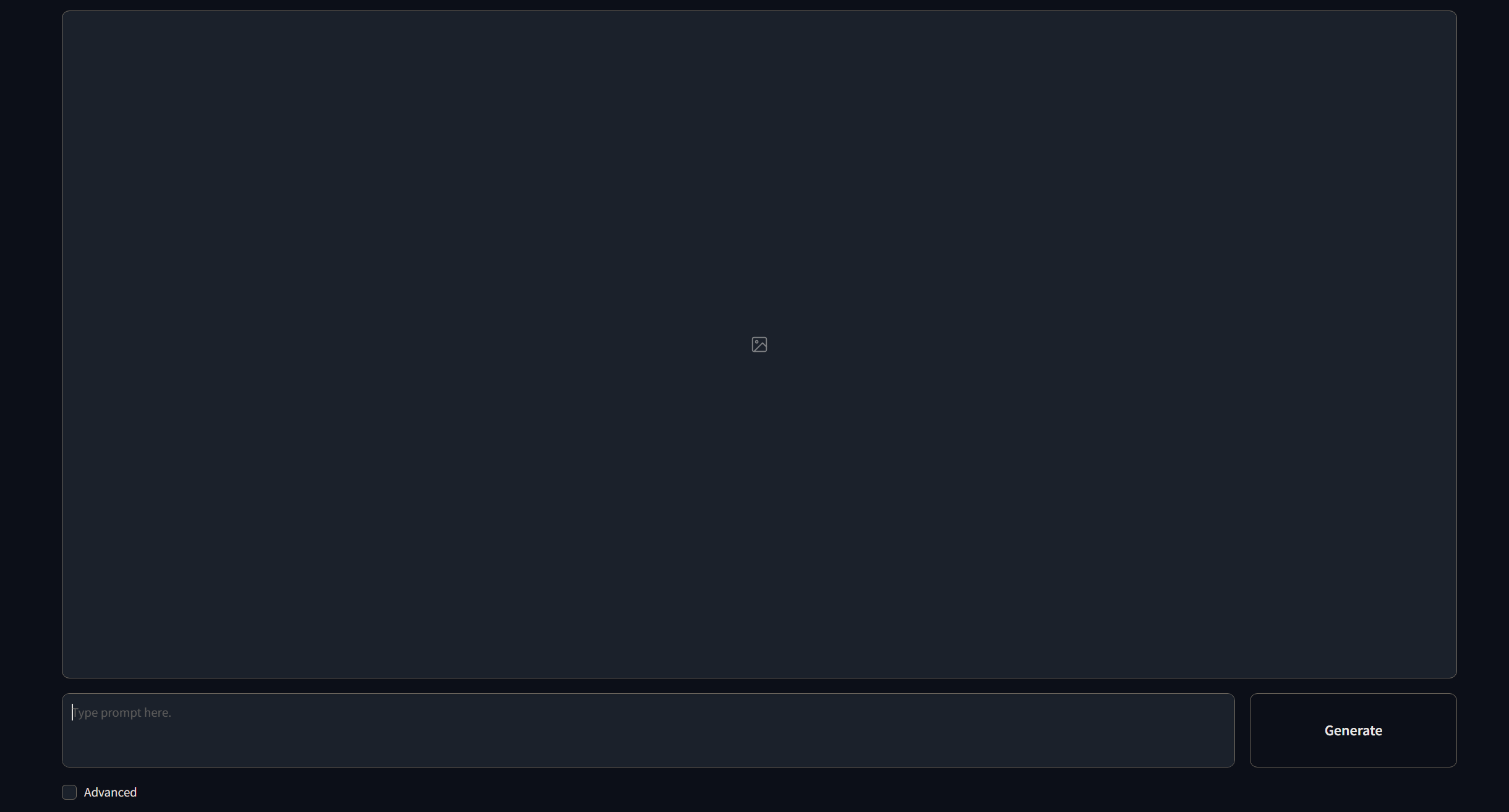
上面是图片预览框,下面是书写提示词的地方(在这里只输入正面提示词)。
开启Advance功能后,侧边栏多出了三个选项。
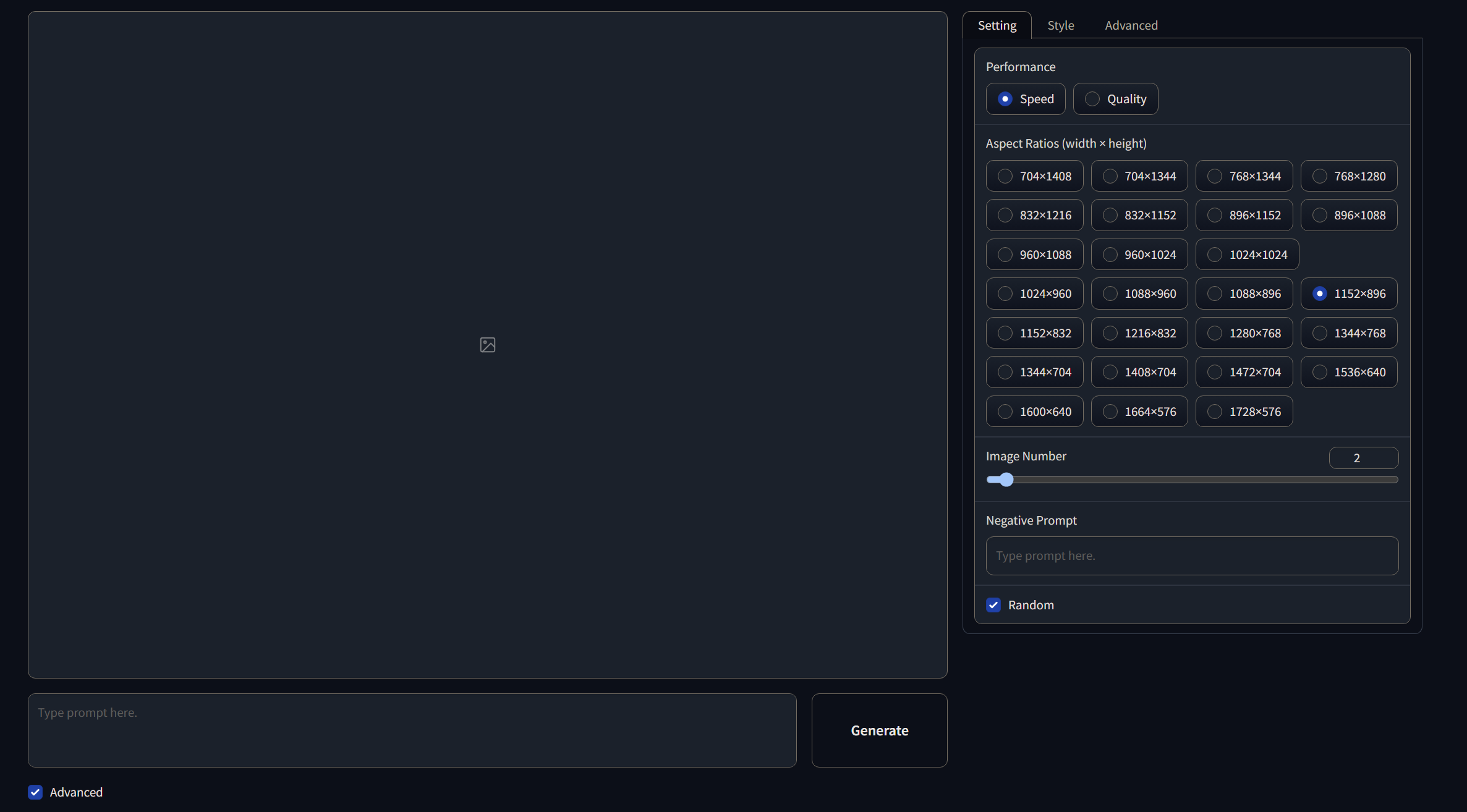
1.“设置”:可以选择注重成图速度或者质量,调节成图分辨率,成图张数,输入负面提示词和设置随机种子。
2.“风格”页面,可以选择出图的风格,将webui中风格提示词的书写简化成了简单的勾选。
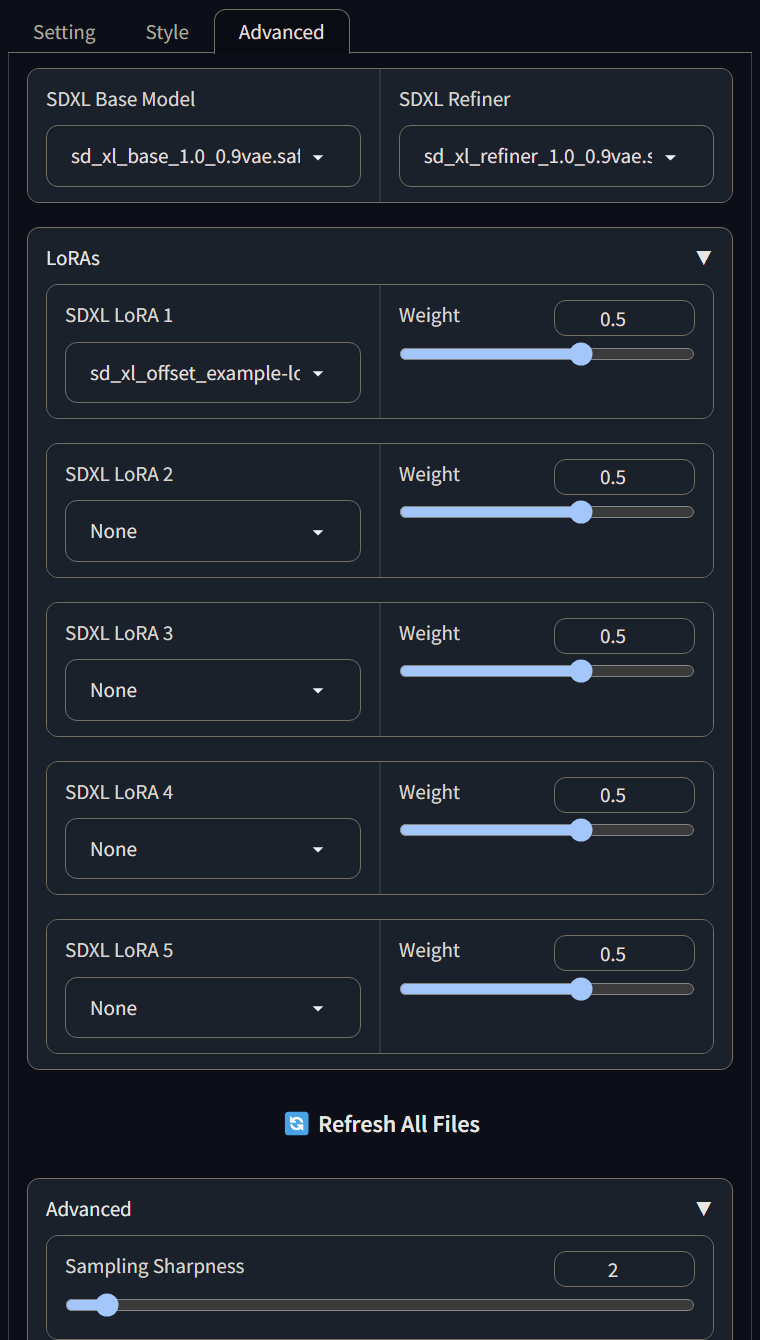
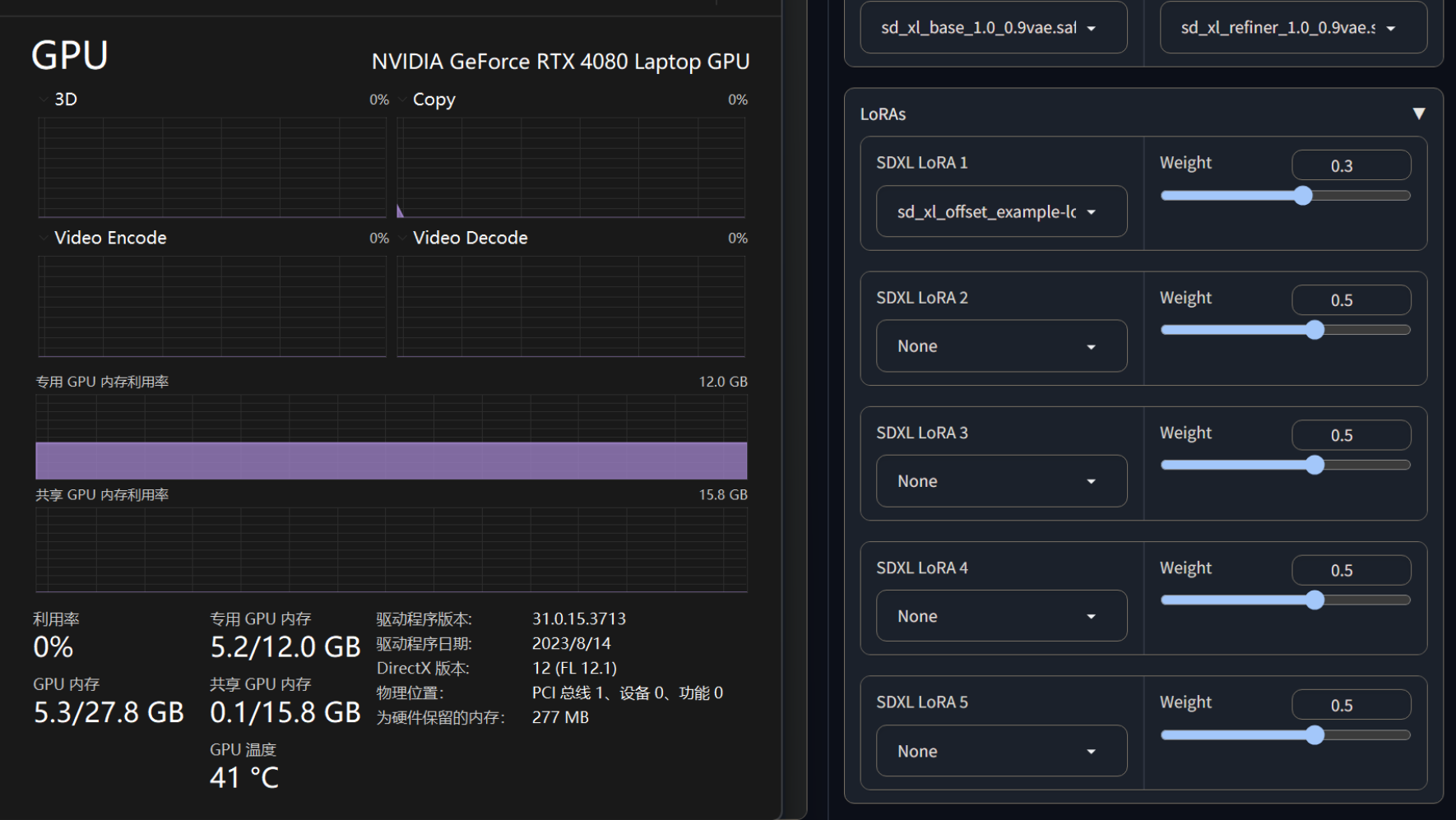
3.“进阶”设置页面,可以选择SDXL的基础模型和refiner模型,还可以调控至多5个SDXL的Lora,最下方的Sampling Sharpness用来控制出图的采样清晰度(实测下来,过高的采样清晰度会导致画面崩坏)。
四、绘图体验
以下为详细测试(均为人工测试结果,仅供参考)
0.使用的硬件:
CPU:i9-13980hx
显卡:4080Laptop 12G,Tesla T4 15G(来自谷歌colab)
内存:英睿达DDR5 4800 16G\*2
固态:致钛7100plus
UI相关
1.1 加载速度
Fooocus的UI界面加载非常迅速,耗时和comfyui一样处在顶尖水平,得益于没有多少插件,Fooocus加载只需要5s左右,comfyui另外还加载了一些插件,耗时8s。
1.2 UI显存占用
空载UI时,显存占用仅有0.2G。
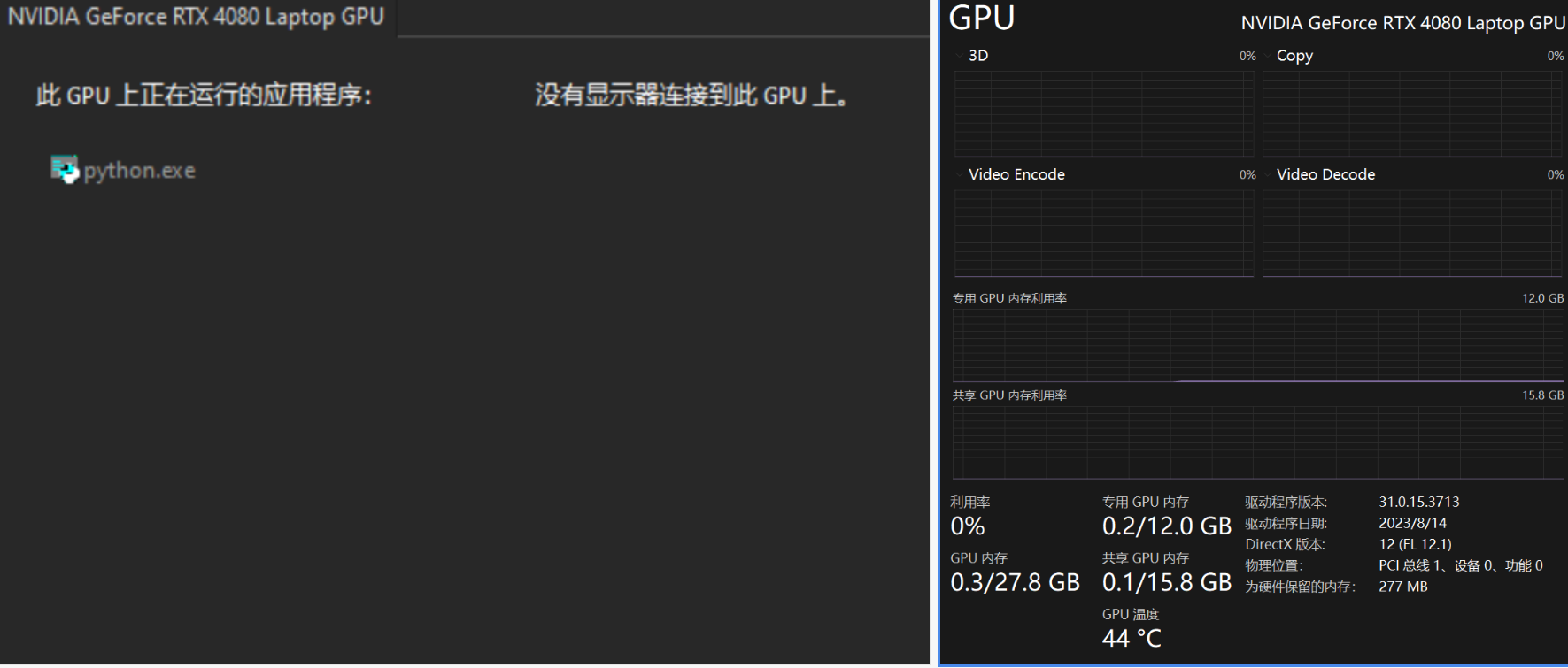
加载SDXL\
base和SDXL\
refiner两个模型之后,显存占用为5.2G,
1.3 绘图体验
绘图显存占用和速度如下
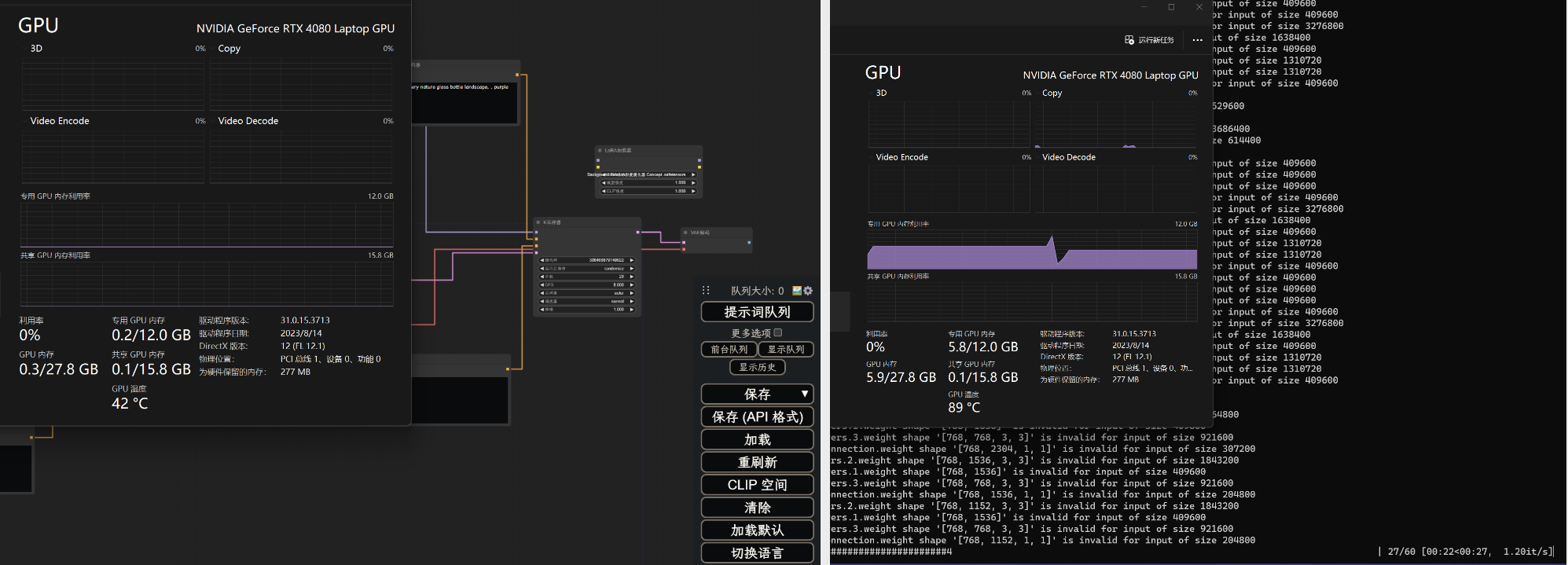
图幅1024\*1024,quality状态生成,Sampling Sharpness=2,以0.3权重加载Lora 1个。
Fooocusui空载时显存占用为0.2G,图幅1024\*1024,quality状态生成,Sampling Sharpness=2,以0.3权重加载Lora 1个。显存占用为6.3G,平均速度为2.58it/s,另外,Tesla T4绘制同图幅的速度为1it/s左右。

作为对比,
comfyui空载时显存占用为0.2,加载相同模型,使用相同迭代步数,生成同样图幅的图片,显存占用为5.8G,平均速度为1.21it/s。
webui空载时显存占用为2.2G,加载相同模型,使用相同迭代步数,生成同样图幅的图片,显存占用为8.3G,平均速度为1.41it/s。
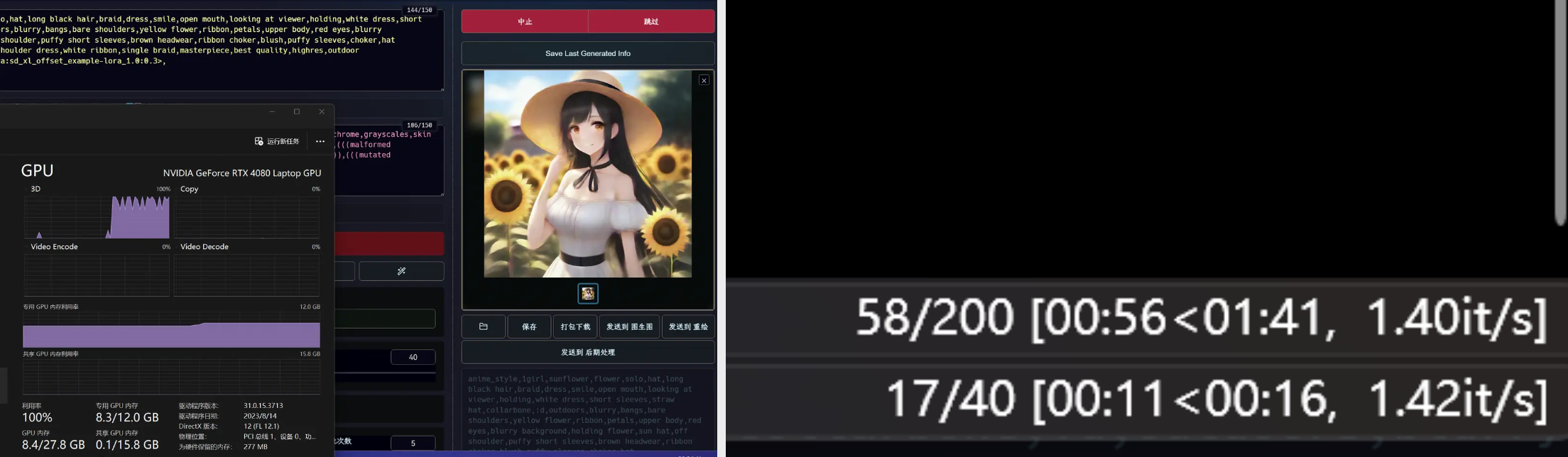
1.4出图质量
我使用以下提示词来测试
正面tag: anime\_style,1girl,sunflower,flower,solo,hat,long black hair,braid,dress,smile,open mouth,looking at viewer,holding,white dress,short sleeves,straw hat,collarbone,:d,outdoors,blurry,bangs,bare shoulders,yellow flower,ribbon,petals,upper body,red eyes,blurry background,holding flower,sun hat,off shoulder,puffy short sleeves,brown headwear,ribbon choker,blush,puffy sleeves,choker,hat flower,frills,day,depth of field,off-shoulder dress,white ribbon,single braid,masterpiece,best quality,highres,outdoor scene,alley,light line,refraction
负面tag: worst quality,((more than one people)),extra people,low quality,bad anatomy,normal quality,lowers,((texts)),monochrome,grayscales,skin spots,acnes,skin blemishes,age spot,(((more than 5 fingers on one hand))),deformity,bad legs,error legs,bad feet,(((malformed limbs))),extra limbs,ugly,((poorly drawn hands)),poorly drawn feet,poorly drawn face,mutilated,(((extra fingers))),(((mutated hands))),mutation,cloned face,disfigured,(((fused fingers)))
SD1.5效果图

Foocusui SDXL效果图

comfyui SDXL效果图

webui SDXL效果图

孰好孰坏是非常主观的事情,我个人也就不在此说明了。
结论(仅针对二次元动漫图片绘制):
①Fooocus确实如同其宣传的那样,可以让用户像使用midjourney一样更专注于提示词,甚至还支持调控5个Lora(这一点已经超越了midjourney)。
②Fooocus仅支持SDXL系列的模型,这对喜欢用SD1.5等早期SD系列模型的用户来说颇为遗憾。
③Fooocus宣称的“经过精心优化过的K采样器”实际是DPM系列采样器的某种变体,然而这种优化采样器的功能在webui中同样也有实现,详见K-diffusion 。与webui原有的那些采样器对比,Fooocus优化过的采样器优势并不是很明显。但是BASE模型和refiner模型可以在成图过程中连续性地使用一个采样器,不仅加强了采样的连贯性,同时也加强了画面创作的延续性,提升了出图效率和稳定性,相信对那些喜欢在webui文生图阶段使用Hires.fix的创作者来说,这一特性别具魅力。
④Foocus无法自定义分辨率,官方解释说这是为了提升出图效率和质量。但对于那些喜欢玩特殊画幅的创作者来说,这一点还是比较遗憾的。解决的办法是Fooocus出图后,在webui或者comfyui中利用inpaint进行扩图,也可以直接用PS的AI生成,后者可控性比较差,尤其在二次元领域。
⑤插件支持较少,并没有webui那样丰富的功能,这也与SDXL支持的插件较少有关,另外Fooocus的初衷也是“专注于提示词”,面向的是SD绘画萌新,对于萌新来说,学会如何书写高质量的提示词,远比学会如何使用插件重要,所以在这一点上,我还是比较认可Fooocus。
⑥UI整体非常轻量化,与comfyui不相上下,官方宣称4G显存也能运行,可能是在启动时针对低显存的显卡添加了特别的启动参数。(后续我换到了Tesla T4 15G,绘制1024\*1024的图片时,显存几乎吃满,由此可见Fooocus在启动时检测了显卡状态,并为不同水平的显卡设定了不同的启动参数)。
⑦绘图速度上,怀疑是特制K采样器的原因,Fooocus quality模式下的绘图速度并不是最快的,但对于臃肿的SDXL模型而言,它的速度也已经非常可观了。
⑧出图质量上,相信大家都有自己的看法,有一点可以明确知晓,那就是Fooocus出图效果和别的ui确实有较大差异。